
Roadmap & Improvements
While the core library management is functional, the project is currently in active development to complete the public-facing experience. My immediate next steps involve building:
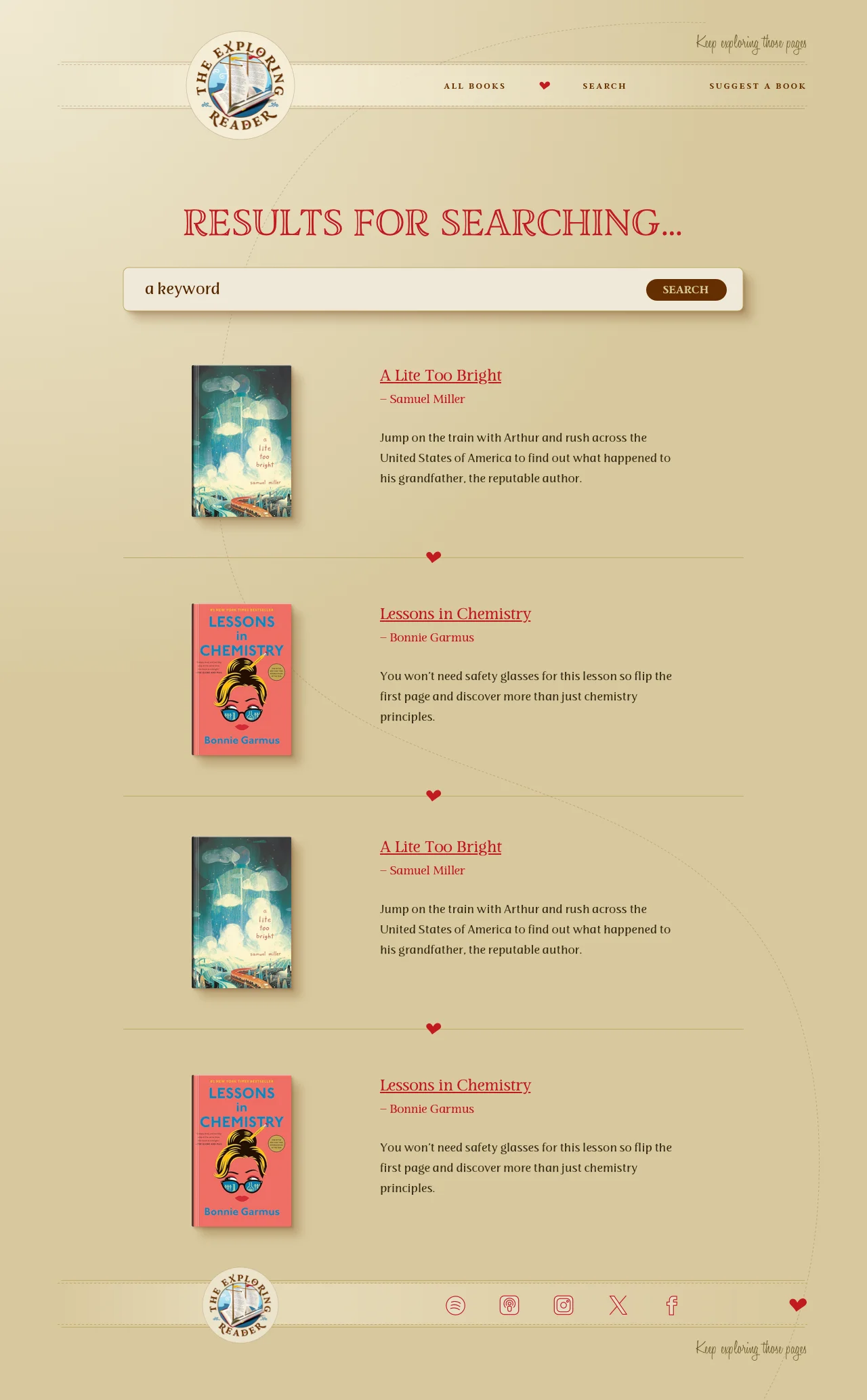
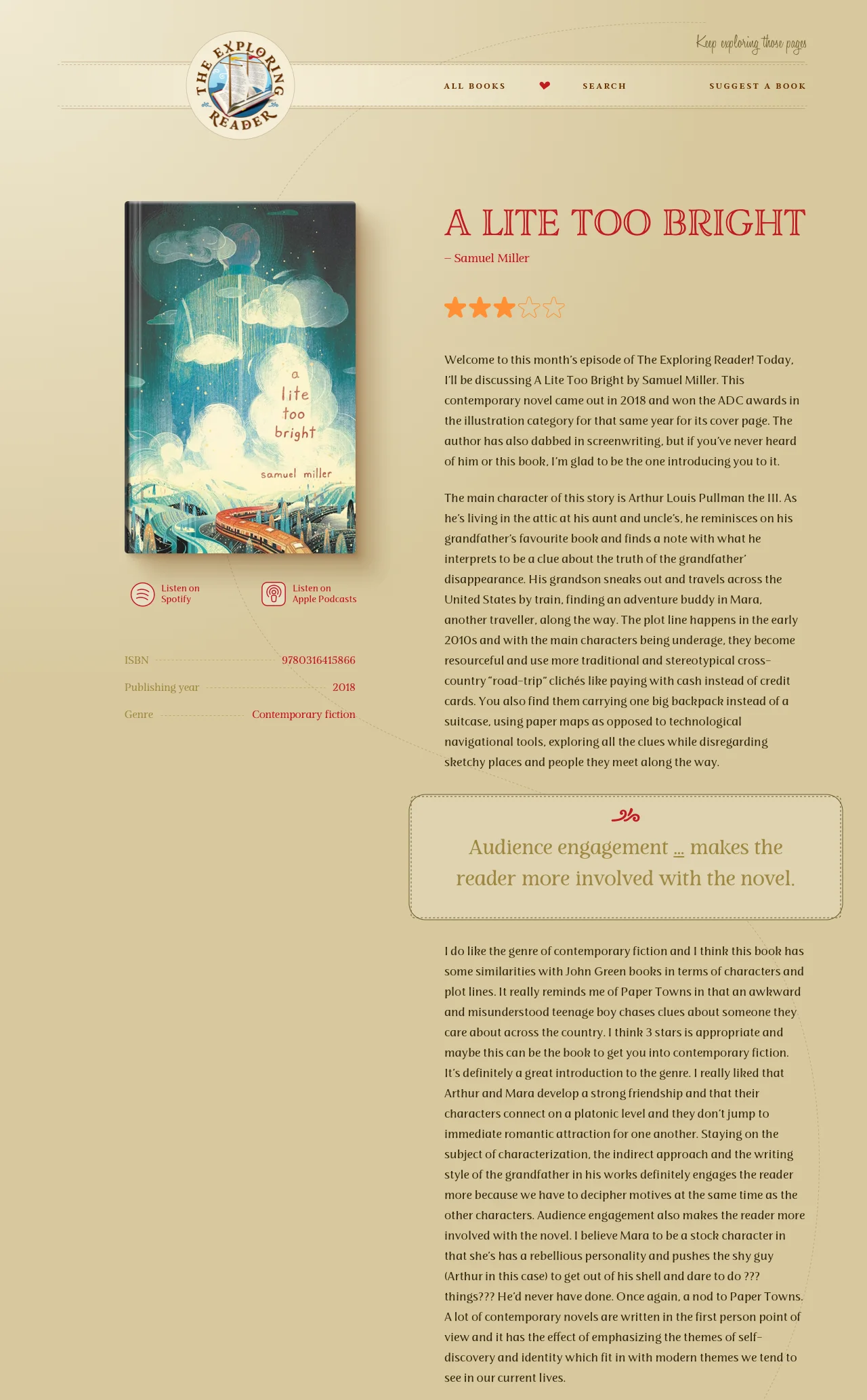
- A Search & Discovery Page: I am implementing a dedicated Search page that allows users to filter the library by genre, author, or episode.
- A Listener Engagement page: I am building a Contact portal where listeners can directly submit book recommendations or feedback to the creator. This feature is designed to turn the website from a static archive into a community-driven platform.
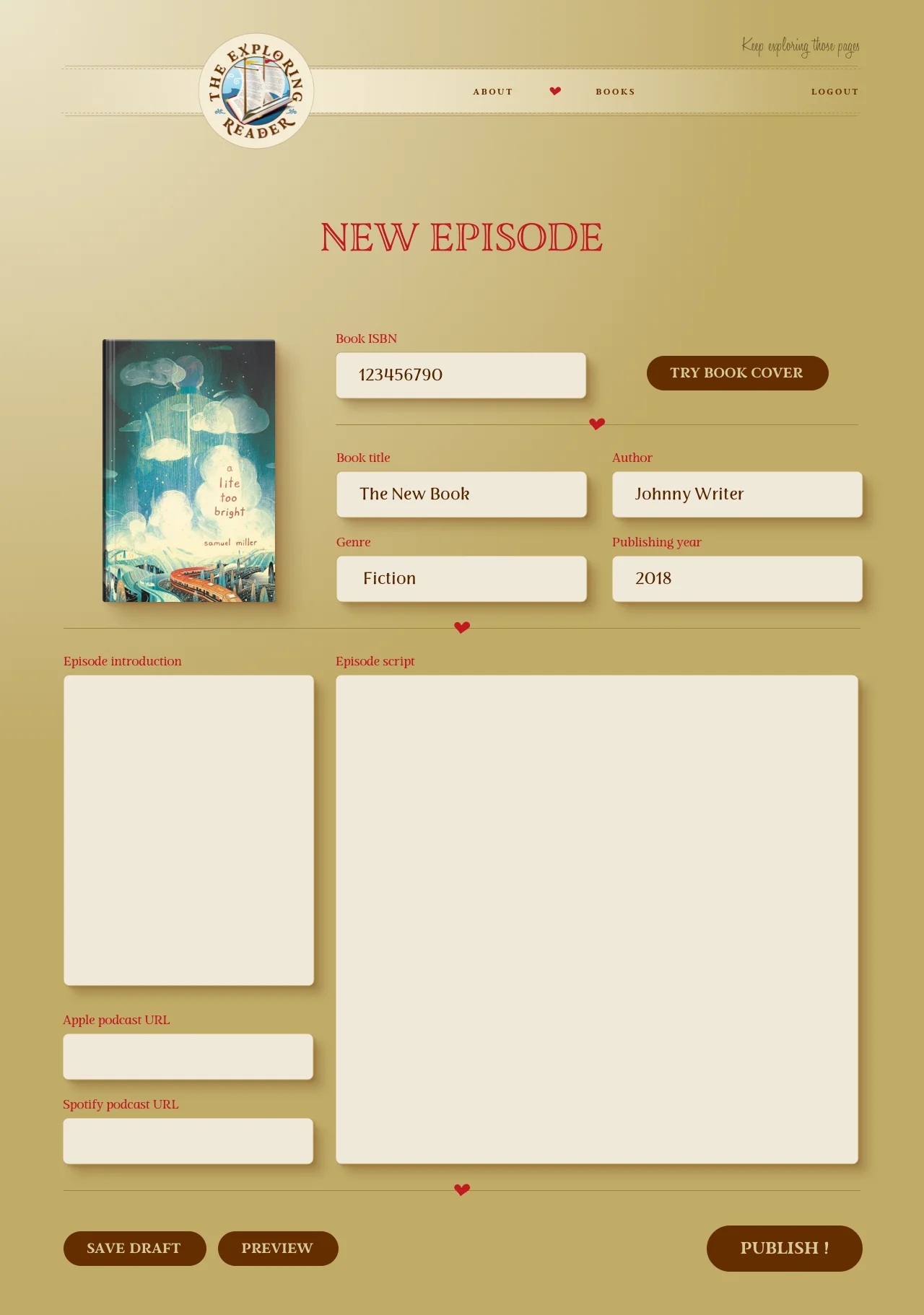
Beyond the original feature set, I am looking for ways to optimize the creator's workflow. Currently, adding an episode requires manual copy-pasting of long transcripts. I plan to implement an Automated Metadata Extractor. Instead of manual entry, the creator would simply provide a link to the episode on Apple Podcasts or Spotify. The backend would then use an API to fetch the episode metadata and potentially interface with a transcription service to pull the text automatically.
Finally, I’m looking into SEO to ensure that each book page is indexed correctly by search engines, helping new listeners discover the podcast through the specific titles they are searching for online.